
Peut-on faire confiance aux détecteurs d’IA ?
Les détecteurs de texte IA sont présentés comme la solution aux questions d’intégrité académique et d’authenticité éditoriale. Mais leur fiabilité réelle est souvent surestimée — et leurs limites, mal comprises. Ce guide analyse honnêtement ce que les détecteurs IA peuvent et ne peuvent pas faire, pourquoi ils se trompent, et comment les utiliser intelligemment sans leur faire une confiance aveugle.
Pour comprendre les méthodes complètes de détection au-delà des outils algorithmiques, consultez notre guide sur les méthodes fiables pour détecter un texte IA. Pour choisir le bon outil, consultez notre comparatif des détecteurs IA disponibles.
Ce que les détecteurs mesurent réellement
Commençons par clarifier ce que fait un détecteur IA — et ce qu’il ne fait pas.
Un détecteur IA ne « reconnaît pas ChatGPT ». Il ne compare pas votre texte à une base de données de textes générés connus. Il ne dispose d’aucun accès aux historiques des outils IA.
Ce qu’il fait réellement : il analyse des patterns statistiques du texte et les compare à des distributions apprises sur des corpus de textes humains et de textes IA. Il calcule principalement :
- La perplexité : à quel point chaque mot est prévisible dans son contexte
- Le burstiness : quelle est la variabilité de la longueur et de la complexité des phrases
- Des patterns de vocabulaire : y a-t-il des structures ou des mots sur-représentés ?
Le résultat est une probabilité statistique, pas une certitude. « 87 % IA » ne signifie pas « ce texte a été écrit par une IA » — ça signifie « les patterns de ce texte ressemblent à 87 % à ceux d’un texte IA dans notre modèle de référence ».
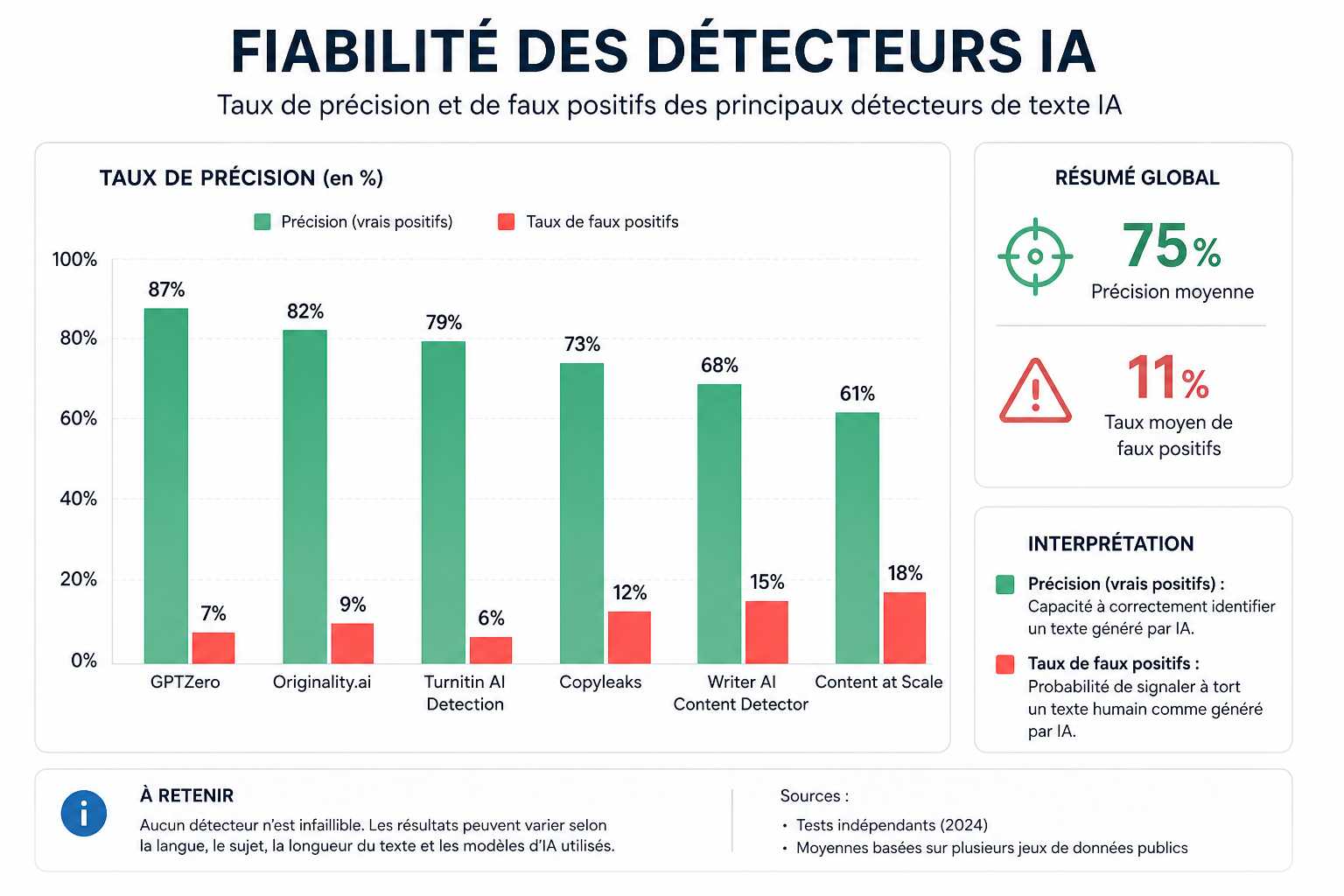
La réalité des taux d’erreur
La plupart des détecteurs revendiquent des précisions de 90 à 99 % dans leurs communications marketing. Ces chiffres méritent d’être contextualisés.
Conditions de test vs réalité
Ces taux sont généralement mesurés sur des textes « purs » — entièrement humains ou entièrement IA, non remaniés, dans la langue d’entraînement du modèle (souvent l’anglais). Dans ces conditions idéales, les meilleurs outils atteignent effectivement des précisions élevées.
Mais en conditions réelles :
- Les textes sont souvent hybrides (partiellement humains, partiellement IA)
- Ils peuvent avoir été paraphrasés ou remaniés
- Ils sont dans des langues autres que l’anglais
- Ils appartiennent à des genres très variés (académique, journalistique, commercial)
Dans ces conditions réelles, les précisions chutent significativement — et les taux d’erreur augmentent.
Les deux types d’erreurs
Les faux positifs (textes humains détectés comme IA) C’est l’erreur la plus problématique dans un contexte académique ou professionnel — accuser à tort quelqu’un d’avoir utilisé une IA.
Des études indépendantes ont montré que certains détecteurs produisent jusqu’à 25-30 % de faux positifs sur des textes académiques légitimes rédigés par des non-natifs anglophones, ou sur des textes de style très formel et régulier.
Les faux négatifs (textes IA non détectés) Un texte IA paraphrasé, remanié ou traduit peut facilement passer sous les radars. La plupart des détecteurs peinent à identifier les textes hybrides (IA + retouche humaine) et les textes IA très courts.
Les limites techniques documentées
Sensibilité à la langue
La très grande majorité des détecteurs IA sont entraînés principalement sur des corpus anglais. Sur le français, l’espagnol, l’allemand ou d’autres langues, leurs performances se dégradent significativement.
Les raisons sont techniques : les modèles de perplexité de référence sont construits sur des langues spécifiques. Un texte en français analysé avec un modèle principalement anglais aura des valeurs de perplexité mal calibrées — augmentant les risques de faux positifs et de faux négatifs.
C’est une limite importante pour les usages francophones — d’où l’importance d’utiliser des outils spécifiquement entraînés sur le français.
Vulnérabilité aux techniques de contournement
Les techniques de contournement — paraphrase, augmentation de température, réécriture manuelle, traduction aller-retour — peuvent significativement réduire les scores de détection. Un texte IA paraphrasé par un outil comme QuillBot peut voir son score chuter de 30 à 50 points de pourcentage selon les tests.
Les détecteurs s’adaptent progressivement à ces techniques — mais c’est une course permanente sans ligne d’arrivée claire.
Les textes courts sont mal analysés
En dessous de 200 à 300 mots, les outils n’ont pas assez de données statistiques pour un diagnostic fiable. Les scores sur les textes courts sont particulièrement variables et peu fiables.
La cohérence inter-outils est faible
Si vous soumettez le même texte à GPTZero, Scribbr et QuillBot simultanément, vous obtiendrez souvent des scores très différents — parfois divergents de plus de 30 points. Cette incohérence est révélatrice du fait qu’aucun outil ne mesure une vérité objective, mais une probabilité calculée selon son propre modèle de référence.
Les faux positifs : le problème le plus sérieux
Le faux positif — accuser un auteur humain d’avoir utilisé une IA — est l’erreur la plus grave dans un contexte d’évaluation académique ou professionnelle.
Les profils à risque élevé de faux positif
Les étudiants étrangers Des études ont montré que les textes rédigés par des locuteurs non natifs en langue anglaise déclenchent des faux positifs à des taux bien supérieurs à la moyenne. Leur écriture, plus formelle et moins idiomatique, ressemble aux patterns IA.
Les textes académiques très formels Un chercheur qui écrit dans un style académique très rigoureux — avec des phrases passives, des structures standardisées, un vocabulaire technique contraint — peut déclencher des scores élevés malgré un travail entièrement humain.
Les styles d’écriture très réguliers Certains auteurs ont naturellement un style homogène et régulier — peu de variabilité dans la longueur des phrases, vocabulaire précis et constant. Ce style présente un burstiness faible qui ressemble à celui des textes IA.
Les traductions Un texte traduit (humainement) d’une autre langue présente souvent des patterns inhabituels qui peuvent déclencher des faux positifs.
Comment utiliser les détecteurs de façon responsable
Ne jamais décider uniquement sur la base d’un score
C’est la règle la plus importante. Un score de détection IA est un signal d’alerte, pas une preuve. Aucune sanction académique ou professionnelle ne devrait être fondée uniquement sur un score algorithmique.
Les institutions qui utilisent ces outils de façon responsable les intègrent dans un processus qui inclut obligatoirement une lecture humaine approfondie, une vérification factuelle, et un entretien avec l’auteur présumé.
Croiser plusieurs outils
Si vous utilisez un outil de détection, croisez les résultats de deux outils indépendants. Si les deux convergent vers un score élevé, la probabilité est renforcée. Si les scores divergent fortement, la situation est ambiguë et ne justifie pas de conclusion.
Contextualiser le score
Un score doit toujours être interprété dans son contexte : quel est le style habituel de l’auteur ? Dans quelle langue a-t-il été rédigé ? L’auteur est-il un locuteur natif ? Le texte a-t-il pu être paraphrasé ?
Un score de 70 % sur un texte écrit par un étudiant étranger dont le style est habituellement formel est bien moins révélateur que le même score sur un texte en anglais idiomatique rédigé par un locuteur natif.
Utiliser des outils adaptés à la langue du texte
Pour les textes en français, utilisez des outils spécifiquement entraînés sur des corpus francophones — comme veriftexte.fr. Les résultats seront significativement plus fiables que ceux d’outils anglophones appliqués au français.
Ce que les détecteurs font bien
Malgré leurs limites, les détecteurs IA ont une utilité réelle :
La détection des textes IA non remaniés en anglais Sur les textes entièrement générés par ChatGPT ou GPT-4 en anglais, sans retouche manuelle, les meilleurs outils atteignent des précisions de 85 à 92 %. C’est utile pour un premier filtre.
L’identification des passages suspects dans les textes hybrides Les outils qui fournissent une heatmap phrase par phrase permettent d’identifier précisément les passages suspects dans un texte mixte — même si le score global est modéré.
L’alerte précoce qui oriente une investigation Un score élevé n’est pas une conclusion — c’est une invitation à investiguer plus avant. Dans ce rôle, les détecteurs sont utiles même avec leurs limitations.
FAQ — Fiabilité des détecteurs IA
Un score de 95 % signifie-t-il que le texte est forcément IA ?
Non. Cela signifie que les patterns du texte ressemblent à 95 % à ceux d’un texte IA dans le modèle de référence de l’outil. C’est une forte probabilité statistique — pas une certitude. Des auteurs humains avec des styles très réguliers peuvent atteindre ces scores.
Les détecteurs peuvent-ils être trompés facilement ?
Oui — une paraphrase manuelle ou automatique réduit significativement les scores de détection. Les outils s’améliorent constamment sur ce point, mais la course aux armements entre générateurs et détecteurs est permanente.
Existe-t-il un détecteur infaillible ?
Non — et il est théoriquement impossible d’en créer un. Tant que l’IA peut imiter n’importe quel style humain, la distinction parfaite restera hors de portée des seuls outils algorithmiques.
Conclusion
Les détecteurs IA sont des outils utiles — mais pas infaillibles. Ils mesurent des probabilités statistiques, pas des certitudes. Leurs limites sont réelles : faux positifs sur les textes formels ou les locuteurs non natifs, vulnérabilité aux techniques de contournement, performances dégradées en français. Utilisés intelligemment — comme premier filtre, croisés avec d’autres outils, intégrés dans un processus humain — ils apportent une valeur réelle. Utilisés seuls, sans contexte ni jugement humain, ils peuvent conduire à des erreurs graves. La lecture humaine attentive reste irremplaçable.